I have been using Claude Code as my main CLI tool for a production ML codebase. It is a document understanding and retrieval system with embeddings, keyword search, and a RAG evaluation layer. Most days it is genuinely useful. You describe a feature, it writes the test, it wires the config, it runs.
But “feels fast” and “is correct” are not the same thing, and vibecoding makes it easy to confuse the two. The agent produces output that looks right. It is fluent, well structured, plausible. And the faster it goes, the less you check. That is the part I want to talk about.
This is not a post about AI coding being bad. It is a taxonomy of the specific ways I have watched it fail on a real codebase, and the cheap defenses I use against each. If you take one thing from it: the failures are few and they repeat. Three of them live in the code. A fourth lives in you. You can defend against all of them, but only if you stop running it on autopilot.
The three failures
After enough sessions, every bad outcome I have seen falls into one of three buckets. (There is a fourth, but it does not live in the code. More on that later.)
-
Stale packages and APIs. The model knows the shape of a library, but last year’s shape. It reaches for functions that no longer exist or were renamed. Signal: it “solves” something with an API you cannot find in the current docs.
-
Hallucinated attributes and methods. It invents config keys, class fields, or method names that sound plausible but do not exist. Signal: the code parses, the tests pass against a permissive config layer, and nothing real is being tested.
-
Poor contextual awareness. It reads related files but not the deciding one, so it reinvents logic that already exists or builds on assumptions that are not true. Signal: it duplicated something, or “extended” a schema it never actually opened.
They are independent. A single turn can trip all three. And they share one uncomfortable property: the output reads as confident whether or not it is true. That is what makes this harder than reading a bad Stack Overflow answer. A wrong Stack Overflow answer feels wrong. A wrong agent answer feels like documentation.
One session, all three
The clearest example I have is a single session. I asked the agent to add keyword search tests to an integration suite. I am keeping the transcript intact because the pattern only makes sense in motion.
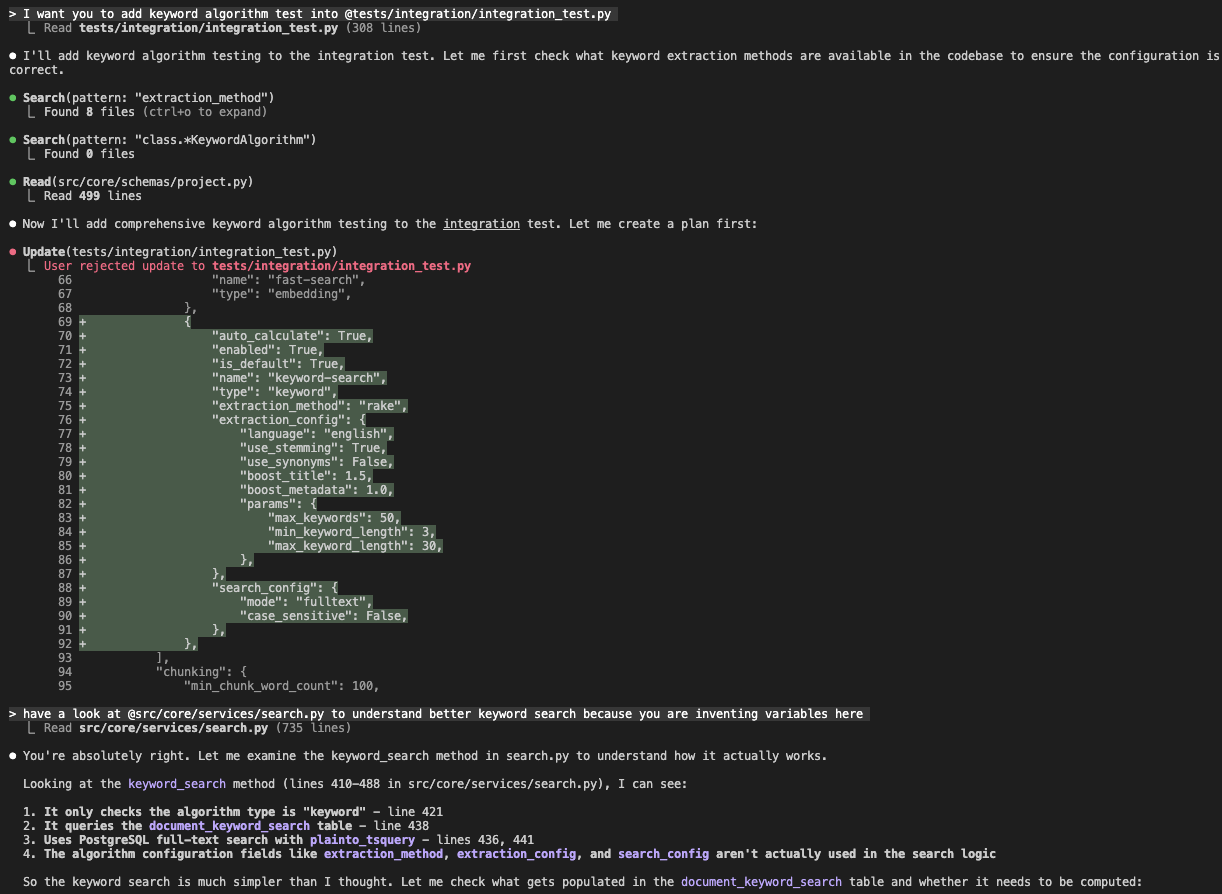
I asked it to add a keyword algorithm test. It did the right-looking thing first. It searched the codebase, read the schema, read the service. Then it wrote this config:
[...]
{
"name": "keyword-search",
"type": "keyword",
"extraction_method": "rake", # invented
"extraction_config": { # invented
"language": "english",
"use_stemming": True,
"use_synonyms": False,
"boost_title": 1.5, # invented
"params": {
"max_keywords": 50, # invented
...
},
},
"search_config": { "mode": "fulltext", ... },
}
[...]
I rejected the edit and told it the truth: you are inventing variables here, go read src/core/services/search.py. It read the file, and then it diagnosed itself, accurately:
Looking at the
keyword_searchmethod (lines 410 to 488), I can see:
- It only checks the algorithm type is
"keyword"- It queries the
document_keyword_searchtable- Uses PostgreSQL full-text search with
plainto_tsquery- The fields like
extraction_method,extraction_config, andsearch_configaren’t actually used in the search logic.
So extraction_method: "rake", boost_title, max_keywords, the whole extraction_config subtree. None of it existed. The agent had assembled a plausible config from the shape of similar configs elsewhere, not from the code. Then it went further and discovered that the feature it was testing “is not fully implemented yet.” It had been writing tests against a fiction.
That one session hits all three failures:
- It reached for
rake, a keyword extraction convention, as if it were wired up here. It was not. (Stale.) extraction_method,boost_title,max_keywords,use_synonyms. Every one invented, every one plausible. (Hallucinated.)- It read related files but not the deciding file until I forced it to. It assumed the schema from a sibling instead of from the source of truth. (Context.)
A blessing and a curse
Here is the part that is hard to convey without living it. The first output felt correct. It was syntactically clean. The keys were sensibly named. The structure matched the surrounding config. If I had not known this codebase, I would have accepted it. The tests would have passed against the config parsing, which is permissive, and silently tested nothing real. A green checkmark over a fiction.

This is the core danger. If you had written it yourself, you would know it was right because you would remember writing it. With an agent, you only know it is right if you verify. And verifying is the thing the tool is implicitly selling you a way to skip.
The defenses
Each failure has a cheap, reliable defense. None of them require giving up on agents.
Against stale APIs, run it and read the release notes. The only honest test for “does this API still exist” is to execute it and read the error. For anything touching an external library, pin the version in the prompt or a project file. When the agent reaches for a function you do not recognize, open the current docs yourself. Better, give the agent a way to read them: an MCP server like DeepWiki lets it query a library’s actual repository on demand, so it grounds its answer in the current source instead of last year’s memory. Treat an unfamiliar API name as a prompt to verify, not as a signal of competence.
Against hallucinated attributes, type check at edit time. This is where a type checker earns its keep. I run ty (or mypy, or pyright) on the agent’s output before I read it. Invented attributes surface immediately as “attribute does not exist.” That is exactly the failure that is hardest to spot by eye. The transcript above is the canonical case. A type checker would have flagged extraction_config, boost_title, and max_keywords the instant the edit landed, with no codebase knowledge required on my part.
Against poor context, force exploration, then plan. Two habits, in order. First, never let the agent write before it has read the deciding file. When I ask for a feature, the first thing I require is: find every place this concept already exists and summarize how it is implemented. If the agent cannot name the file that defines the schema, it is not ready to extend the schema. Second, plan before you code. Use planning mode to brainstorm the feature end to end, including corner cases, before a single edit. The plan forces the agent to commit to an understanding you can check. In the transcript above, a plan step would have surfaced “I haven’t found where keyword extraction is implemented” before any config was written. One thing that makes a difference is to explain your context, where you are comming from and where you want to go to the model.
Encode all of the above in a project memory file. Whatever your agent calls it, CLAUDE.md, AGENTS.md, a copilot custom prompt, keep a project-level file that turns each defense above into a standing rule. Mine is roughly this:
## Working in this repo
- Read the file that defines a symbol before you use it. If you can't
name that file, you are not ready to write the code.
- Never invent config keys, fields, or methods. If it isn't in the
source, it does not exist. Quote the line you found it on.
- Prefer the existing pattern in `src/core/services/` over a new
abstraction. Search before you build.
- Plan first: list the files you read and what each one decides,
before any edit.
- Run the type checker (`ty`) and the test you touched before you
report done. "Done" means green, not written.
This is the highest-leverage mitigation because it runs on every session without you repeating it. Your conventions become the agent’s prior.
The Gell-Mann problem
Here is the fourth failure I promised, and it is the one that should keep you up at night. As I said, it does not live in the code. It lives in you.
Michael Crichton named the Gell-Mann Amnesia effect. You read a newspaper article about a field you know deeply, spot that it is riddled with errors, turn the page to a field you do not know, and proceed to believe every word. You forget, instantly, that the same publication was just wrong.
Vibecoding is the Gell-Mann effect, scaled up. When the agent writes code in your area of expertise, you catch the inventions immediately. There is no extraction_method field, what are you doing. That is reassuring. It feels like the agent is mostly right and you are just cleaning up edges. Then you ask it about a domain you are less sure of, a niche library, an unfamiliar protocol, a part of the stack you have never touched, and it writes with the exact same confidence. And because you cannot catch it there, you accept it.
The fluency is constant. The accuracy is not. You cannot use your own detection rate in your expert domain to estimate your detection rate in a domain you do not know. In the expert domain you are a filter. Outside it, you are a rubber stamp. Every “it looks right” outside your expertise is uncalibrated, including the ones you are sure about.
This is why the process defenses matter more than the content defenses. Type checking, running the code, forcing the agent to prove it read the source. These work in domains where your own judgment cannot. “I’ll just check it myself” is a defense that silently disappears the moment you need it most.
What this reveals about the models
Zoom out, and these three failures tell you something about where the models still break, and where the next gains are.
Stale APIs are a data freshness problem. The model knows the shape of a library. It just knows last year’s shape.
Hallucinated attributes are a grounding problem. Nothing in the training loop forces invented symbols to resolve against a real codebase.
Poor context is an agentic problem. The model does not yet reliably decide what to read before it writes.
All three are exactly the things being attacked right now with tool-grounded RL and agentic training environments. Models are rewarded for running code, penalized for referencing symbols that do not resolve, and trained to explore before acting. Today’s vibecoding failures are, almost point for point, the benchmark the next generation is being optimized against. Which is why the defenses above are not a permanent tax. They are a bridge. Use them while the bridge is still standing.
The honest version of the vibecoding pitch is not “the agent writes your code.” It is “the agent writes code at the boundary of what it can verify, and your job is to push that boundary out, with type checkers, with tests, with project memory, and with the discipline to never trust fluent output you have not run.” Do that, and it is useful. Skip it, and you are shipping plausible fiction.
What is the failure mode you keep hitting that I missed? I am collecting these. The taxonomy above is almost certainly incomplete.